Note: If you are unable to locate the answers you need, please see our TMF Bot FAQ.
Note: Users cannot edit the Prediction Confidence Threshold for system-trained models.
Note: To enable auto-classification and metadata extraction functionality for documents in languages other than English, contact Veeva Services to enable the Multilingual Model feature.
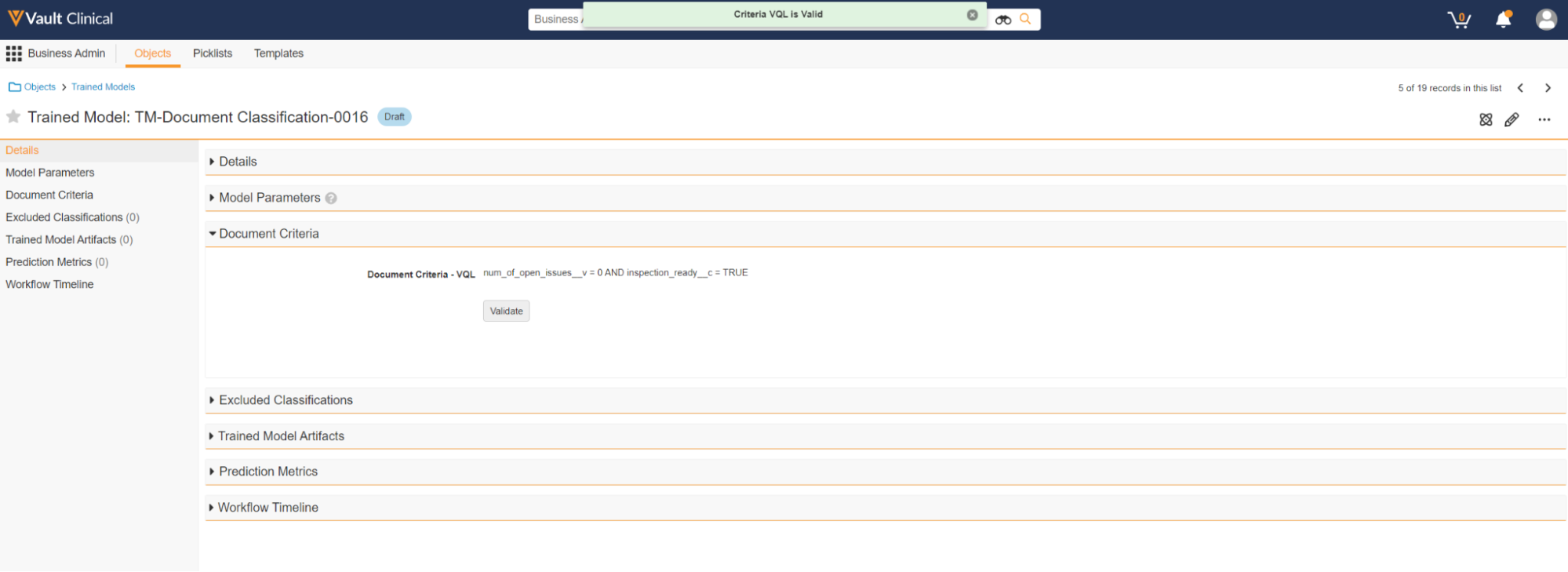
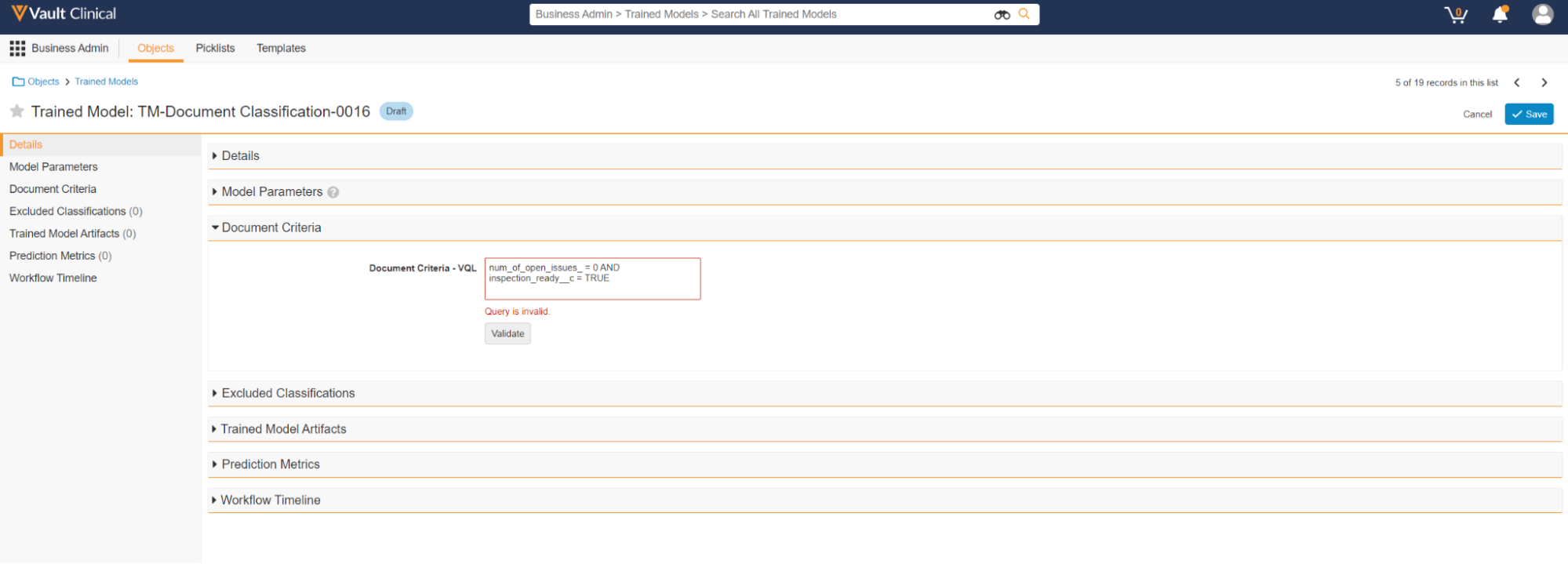
If the query is invalid, Vault displays an error message below the **Document Criteria - VQL** field.
 Once you train the model, Vault automatically sets the **Training Set Type** to **Document Criteria**.
### Training Window Start Date
To train your model, you'll need to choose a method to pull documents to use as input in this _Trained Model_ using the _Training Window Start Date_.
This method pulls all documents in a Steady State, such as Approved or Final, with a Version Created Date value between the Training Window Start Date and the current date. If there are more than 200,000 documents that fit this criteria, Vault uses the 200,000 most recent documents. You must ensure you have filled in a Training Window Start Date value on your _Trained Model_ record.
### Creating Excluded Classifications
You can define classifications to be excluded from your Trained Model, so that the documents will never be updated automatically for these classifications, but only manually.
You can specify excluded classifications before or after a model is trained and the behavior will differ depending on when the exclusion is added:
* If you add an excluded classification before the model's training, the TMF Bot excludes the specified classification(s) from all extraction, training, and testing during model deployment. The excluded classifications are then not known by the Bot which can only predict a trained classification.
* If you add an excluded classification after the model's training, the model is not automatically retrained, meaning TMF still knows the excluded classifications but the TMF Bot will not take any action against documents predicted for the excluded classification.
In general, we recommend the following best practices:
* Excluding prior to the model training all the "Non-TMF" / working zone classifications.
* Excluding after the model's training all the monitoring classifications that you expect to be generated by the system when you use Veeva CTMS.
* Not excluding classifications before model training because you think the Bot will perform poorly.
Once you train the model, Vault automatically sets the **Training Set Type** to **Document Criteria**.
### Training Window Start Date
To train your model, you'll need to choose a method to pull documents to use as input in this _Trained Model_ using the _Training Window Start Date_.
This method pulls all documents in a Steady State, such as Approved or Final, with a Version Created Date value between the Training Window Start Date and the current date. If there are more than 200,000 documents that fit this criteria, Vault uses the 200,000 most recent documents. You must ensure you have filled in a Training Window Start Date value on your _Trained Model_ record.
### Creating Excluded Classifications
You can define classifications to be excluded from your Trained Model, so that the documents will never be updated automatically for these classifications, but only manually.
You can specify excluded classifications before or after a model is trained and the behavior will differ depending on when the exclusion is added:
* If you add an excluded classification before the model's training, the TMF Bot excludes the specified classification(s) from all extraction, training, and testing during model deployment. The excluded classifications are then not known by the Bot which can only predict a trained classification.
* If you add an excluded classification after the model's training, the model is not automatically retrained, meaning TMF still knows the excluded classifications but the TMF Bot will not take any action against documents predicted for the excluded classification.
In general, we recommend the following best practices:
* Excluding prior to the model training all the "Non-TMF" / working zone classifications.
* Excluding after the model's training all the monitoring classifications that you expect to be generated by the system when you use Veeva CTMS.
* Not excluding classifications before model training because you think the Bot will perform poorly.
Note: This exclusion applies only to the Trained Model to which the Excluded Classification belongs. For example, let’s say you have Trained Models deployed for Auto-Classification and Metadata Extraction, and your Metadata Extraction model has an Excluded Classification for “Protocol”. You then create a document that the TMF Bot thinks is a Protocol belonging to study AVEG 027. The TMF Bot will classify the document as a Protocol, but it will not set the Study field because the Protocol is an Excluded Classification for Metadata Extraction.
Note: Vault automatically refreshes deployed Trained Models every general release.
Note: Each combination of Trained Model and Field Extracted will have one set of Metadata Extraction prediction records. This means that in a Vault with both an Auto-classification Trained Model and a Metadata Extraction Trained Model, Vault calcuates prediction metrics for Auto-classification, Study, Study Country, and Site.