注意:如无法找到您需要的答案,请查看我们的 TMF 机器人程序常见问题。
训练 TMF 机器人程序模型完成之后,有大量数据可用于帮助您评估您的训练模型的有效性。本文介绍如何使用我们的关键指标评估您的训练模型,如何定义其提供的各个训练模型构件,以及如何识别问题并改进您的模型训练。
此外,Vault 还会为自动分类性能提供标准报告。
评估关键指标
关键指标定义
有三种关键指标可确保您的训练模型的有效性:提取覆盖范围、自动分类覆盖范围和自动分类错误率。本部分包含对各个和其中一些建议目标和基于实际训练模型的真实示例值的基本描述。
| 指标 | 定义 | 带来该结果的驱动因素是什么? | 建议目标 | 示例 |
| 提取覆盖范围 | 拥有可用于训练模型的适当信息的文档数量 | 符合我们的提取标准的文档(可提取文本、英语文本) | 50-90%,较低端的文档适合非英语客户 | 主要为基于英语的企业客户在其 200,000 份最新文档上对模型进行训练;其提取覆盖范围为 85.34% |
| 自动分类覆盖范围 | 其预测值高于您的预测置信阈值的文档数量 | 您的预测置信阈值,以及用于训练的文档的数量和准确度 | 45-95%,较低端的文档适合使用较少文档数 (<5,000) 开展训练的客户 | 拥有 90预测置信阈值的客户能够实现 94% 的自动分类覆盖范围,而拥有 99预测置信阈值的客户可实现 89.65% 的自动分类覆盖范围 |
| 自动分类错误率 | 其预测高于您的预测置信阈值且被错误分类的文档 | 您的预测置信阈值,以及用于训练的文档的数量和准确度 | 您对该指标的目标将取决于您所在组织的风险规避能力。通常该值越低越好,请谨记:
| 拥有 0.90 预测置信阈值的客户的自动分类错误率为 0.58%,而拥有 0.99 预测置信阈值的客户可实现 0.28% 的自动分类错误率 |
使用关键评估指标
在以上节段中,我们介绍了可用于评估您的训练模型的有效性的三个关键指标。您可在训练概述结果字段中找到该指标。
提取覆盖范围
提取覆盖范围是唯一一个您无法改进的关键指标。尽管这有点令人困惑,但该指标的目的是为添加至文档收件箱中的文档设置适当的期望值。如果贵公司有多个音频、视频或其它非文本文件,大量非英语文档或经常遇到扫描字迹模糊的问题,该指标可帮助您了解为什么文档收件箱中的特定文档未进行自动分类。
自动分类覆盖范围
您可通过以下方法改进您的自动分类覆盖范围指标。
- 降低您的预测置信阈值,较低的预测置信阈值可使更多文档纳入自动分类范围,但是应注意,这可能会提高您的自动分类错误率。
- 在模型结果混淆矩阵中评估异常值:异常值不在矩阵的对角线上。您可能会发现,一些文档类型经常会混淆。您可通过在您的 Vault 中重新分类文档或通过从训练中删除特定文档类型减少此类错误。您将需要训练新的训练模型记录,以记录此类变更。
自动分类错误率
您可通过以下方法改进您的自动分类错误率指标。
- 提高您的预测置信阈值:较高的预测置信阈值可降低错误率,因为这会提高模型的自动分类置信度,但是应注意,这可能会缩小您的自动分类覆盖范围。
- 评估模型结果单独预测CSV 中超出您的预测置信阈值但是被错误分类的文档。在您的 Vault 中评估此类文档可验证 TMF 机器人程序是否正确,以及文档是否出现手动错误分类。或者,TMF 机器人程序是否仍然发送错误,这可帮助您了解发生该情况的原因。
完成评估
评估您的训练模型关键指标之后,您可将其与我们的建议目标进行比较,并制定您自己的公司目标。如果您的训练模型符合或超出您设定的目标,该模型即为可部署的优良训练模型。
训练模型性能指标
训练完成后,每个训练模型会拥有一系列训练模型性能指标记录。您可在您的训练模型记录中的模型性能指标部分找到此类记录。有三类指标类型可用于文档分类训练模型:
- 通用加权平均值:包含平均精确率、召回率和 F1 评分,通过各类分类中的文档数量进行加权计算。
- 通用非加权平均值:包含全部分类的平均精确率、召回率和 F1 评分,不考虑各个分类中的文档数量。
- 分类性能:包含指标子类型中列出的文档类型的精确率、召回率和 F1 评分。
- 一项特殊的其它未知分类性能记录会收集分类中不符合每个文档类型的最少文档数阈值的文档。此类文档仍可在训练中使用,但是会汇总在一起,用以改进有效分类的预测。
每条记录会显示以下指标:
- 精确率:表示所做预测的准确性概率
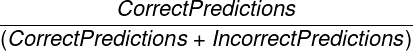
- 召回率:该指标子类型中进行正确预测的项目所占的百分比
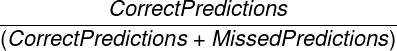
- F1 评分:表示精确率与召回率之前的平衡

- 训练文档:用于训练模型的文档的数量。将为用作输入数据的总文档数的 80%。该 80% 文档将从个分类中随机选取。
- 测试文档:用于测试模型的文档的数量。将为用作输入数据的总文档数的剩余 20%。
- 正确预测数:模型正确预测出分类的总次数,不考虑预测置信度。
- 超出阈值的预测数:超出该训练模型上选择的预测置信阈值的总预测数。
- 超出阈值的正确预测数:超出该训练模型上选择的预测置信阈值的总体正确预测数。
需注意:所有正确执行的预测均假设输入文档进行了正确分类。使用错误分类的文档训练模型可能会导致错误的自动分类。下列训练模型构件可帮助发现潜在问题。
训练模型输出
训练模型拥有一系列附加训练模型构件,每个构件均包含重要的数据。您可在训练模型构件部分的训练模型对象记录中找到此类构件。构件包括以下使用文档分类类型的训练模型:
- 文档集合提取结果(文档集合_提取_结果.csv):提取训练该模型所需的每个文档的结果。
- 该文件在查看为什么训练过程中未使用某些文档方面最有帮助。
- 您可使用该文件中的文档 ID 和主要/次要版本查看 Vault 中的适当文档。
- 参见以下提取失败的原因,了解一些潜在失败原因。
- 模型结果混淆矩阵 (model_results_confusion_matrix.csv):比较文档的实际分类(X 轴)和 TMF 机器人程序的预测分类(Y 轴)
- 对角线上应分布最多的数量,因为实际的分类和预测的分类会相交于此处。
- 数量高于和低于对角线表明发生了混淆。您应检查出现大量错误预测的分类,以了解出现训练模型混淆的原因。
- 模型结果文档类型频率 (model_results_doctype_frequency.csv):列举出使用的全部文档类型、各个分类中使用的总文档数以及分别用于训练 (80%) 和测试 (20%) 的文档数量。低于每个文档类型的最少文档数的分类将归入其它未知类别中。
- 模型结果单独预测 (model_results_individual_predictions.csv):显示实际文档类型、编码文档类型、前三项预测、各个文档的前三项预测评分,以及文档是否错误分类。
- 实际文档类型列列出 Vault 中的实际分类。编码文档类型列显示您向模型提供的对象:实际分类或其它未知类别,后者用于数量少于训练模型的每个文档类型的最少文档数的文档类型。
- 该文件显示三个预测评分,每个评分对应一项文档类型预测。自动分类仅使用第一预测评分。如果该评分高于预测置信阈值,该文档将进行自动分类。第二和第三评分仅用于说明性目的。
- 最后,错误分类将显示编码文档类型与第一文档类型预测是否相匹配。通过筛选查看错误分类项目可快速发现您现有文档的潜在问题。例如,如果训练模型的第一预测评分为 9999887 并且进行了错误分类,则文档可能在您的 Vault 中进行了错误分类。
- 模型结果性能指标 (model_results_performance_metrics.csv):是该记录中模型性能指标的 CSV 版本。
- 模型结果训练集合 (model_results_training_set.csv):列出了用于训练的单独文档(整个文档集合的 80%)及其分类。如果您希望查看用于训练特定分类的文档,尤其是您注意到经常出现错误分类时,该文件会非常有用。
提取失败的原因
文档集合提取结果CSV 文件会提供以下其中一个提取失败原因:
- 未识别到语言:系统无法识别到语言
- 语言不支持:识别到的语言不是英语
- 语言识别置信度低:系统对语言识别的置信度较低
- 无可用文本:文档没有可提取的文本
- 为 PDF 执行 OCR 失败:无法为 PDF 文件完成光学文字识别 (OCR)
- 为复杂图像执行 OCR 失败:无法为复杂图像格式(例如 TIFF)完成 OCR
- 为简单图像执行 OCR 失败:无法为简单图像格式(例如 PNG 或 JPG)完成 OCR
- 呈现 PDF 失败:TMF 机器人无法将文档作为 PDF 呈现
- 当前文档类型为非活跃状态:该文档的文档类型已再不是活跃状态
- 未找到稳定状态:文档没有文档状态的版本
- 文档类型被故意排除在外:文档为活页夹或属于 TMF 文档或最终 CRF 文档类型
TMF 机器人报告
Vault 包含标准报告和报告类型,以帮助评估所部署模型的性能。
预测报告类型
您可以使用预测报告类型为 TMF 机器人性能构建自定义报告。
预测指标报告类型
您可以使用预测指标报告类型查看有关经过培训的模型性能的详细信息。
TMF 机器人结果 - Excel 报告信息板
这份预配置的预测报告包含训练模型的提取覆盖范围、自动分类覆盖范围和自动分类成功率。您也可以导出此报告的一个 Excel 模板,其中包含一个用于显示模型性能的信息板。