Note: タイトル:必要な回答が見つからない場合は、TMF ボット FAQ をご確認ください。
TMF ボットモデルの教育訓練後は、お使いの教育訓練モデルの効果を評価するための多くのデータを利用できます。この記事では、主要な指標を使用して、お使いの教育訓練モデルを評価する方法を説明し、提供される各教育訓練モデルの生成物を定義し、問題を特定してモデルの教育訓練を改善する方法を説明します。
また、Vault は自動分類パフォーマンスで 標準レポートを提供します。
評価主要指標
主要指標の定義
教育訓練モデルが実行可能であることを確保するために 3 つの主要な指標があります: 抽出範囲、自動分類範囲、自動分類エラー率。このセクションでは、それぞれの基本的な説明と、推奨されるターゲットと実地の教育訓練モデルに基づく実例値を紹介します。
| 指標 | 定義 | この結果は何によってもたらされたか? | 推奨ターゲット | 例 |
| 抽出の範囲 | モデルの教育訓練に適切な情報を持ったドキュメントの数 | 抽出基準に適合したドキュメント (抽出可能なテキスト、英語のテキスト) | 50–90%、英語以外のお客様にはこの下限が適切です | 主に英語をベースとする企業のお客様が、最新のドキュメント 200,000 件でモデルの教育訓練を実施した結果、抽出の範囲は 85.34% でした。 |
| 自動分類の範囲 | 予想確実性基準値を上回る予測をしていたドキュメントの数 | 教育訓練に使用されたドキュメントの正確性および数に加えて、自身の予想確実性基準値 | 45–95%、少数のドキュメント (<5,000) で教育訓練を行うお客様にはこの下限が適しています | 予想確実性基準値が .90 のお客様の自動分類範囲が 94% であったのに対し、予想確実性基準値 が .99 の同じお客様の自動分類範囲は 89.65% でした |
| 自動分類エラー率 | 予想確実性基準値以上の予想値を持つドキュメントのうち、不正確に分類されたもの | 予想確実性基準値、および教育訓練に使用されたドキュメントの数および正確性。 | このターゲットは、お客様の組織がどの程度リスク回避型であるかによって異なったものとなります。通常は低い方が適切とされていますが、以下の点に留意してください:
| 予想確実性基準値が .90 のお客様の自動分類エラー率が 58% のであったのに対し、予想確実性基準値 が .99 の同じお客様の自動分類エラー率は .28% でした |
評価で主要指標を使用する
上記のセクションでは、教育訓練モデルの効果を評価するための 3 つの主要指標を紹介しました。これらは、教育訓練概要結果フィールドに表示されます。
抽出の範囲
抽出範囲は、主要指標の中では改善できない唯一の指標です。戸惑われるかもしれませんが、この指標の目的はドキュメントインボックスに追加されるドキュメントに正しい予想を設定することです。会社に多数のオーディオ、ビデオ、その他のテキスト以外のファイルがある場合、または英語以外のドキュメント、または不鮮明なスキャンで定常的に問題が発生するドキュメントが非常にたくさんある場合、この指標は特定のドキュメントがドキュメントインボックスに自動分類されない理由を理解する役に立つことがあります。
自動分類の範囲
自動分類の範囲指標は、以下の方法で改善することができます:
- 予想確実性基準値を下げる: 予想確実性基準値を下げると、より多くのドキュメントが自動分類の範囲に入る可能性がありますが、自動分類エラー率が上昇する可能性があることに注意してください。
- モデル結果混同マトリックス内の外れ値を評価します: 外れ値はマトリックスの対角線上にはありません。一部のドキュメントタイプで定期的に混同が起こっていることもあります。これは、Vault ないでドキュメントを再分類するか、特定のドキュメントタイプを教育訓練から除外することで減らすことができます。これらの変更を取得するためには、新規の教育訓練モデルレコードを教育訓練する必要があります。
自動分類エラー率
自動分類エラー列指標は、以下の方法で改善することができます:
- 予想確実性基準値を上げる: 予想確実性基準値を上げると、自動分類におけるモデルの確実性が上がってエラー率が低下する可能性がありますが、自動分類の範囲も減少する可能性があることにご注意ください。
- 予想確実性基準値を上回るものの、誤って分類されているドキュメントをモデル結果の個別予想 CSV 内で評価します。Vault 内でこれらのドキュメントを評価すると、TMF ボットが正しく、ドキュメントが実際に誤って分類されていることが明らかになることがあります。または、TMF ボットがやはり誤っていて、その理由がわかることもあります。
評価の終了
教育訓練モデルの主要評価指標を評価したら、推奨ターゲット値と比較してターゲット値を設定します。教育訓練モデルが設定されたターゲットを満たすか超えていれば、導入に適した良好な教育訓練モデルとなります。
トレーニング済みモデルパフォーマンス指標
教育訓練が完了すると、各教育訓練モデルに一連の教育訓練モデルパフォーマンス指標レコードが作成されます。これらは、教育訓練モデルレコードのモデルパフォーマンス指標セクションで確認できます。ドキュメント分類教育訓練モデルには 3 つの指標タイプが存在します:
- グローバル重み付け平均: 各分類のドキュメント数によって重み付けされた平均予想、リコールおよび F1-スコアが含まれます。
- グローバル非重み付け平均: 各分類のドキュメント数に関わらず、すべての分類の平均予想、リコールおよび F1-スコアが含まれます。
- 分類パフォーマンス: 指標サブタイプにリストされるドキュメントタイプの予想、リコールおよび F1-スコアが含まれます。
- 特殊なその他の不明分類パフォーマンスレコードには、ドキュメントタイプごとの最小ドキュメント数基準値に達しない分類のドキュメントが入ります。これらのドキュメントは引き続き教育訓練で使用されますが有効な分類についての予想によりよい情報を提供するためにグループ化されます。
各レコードは以下の指標を示します:
- 精度: 予想が正確であった頻度
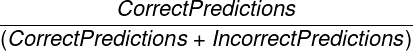
- リコール: 正しく予想されたこの指標サブタイプ内の項目の割合
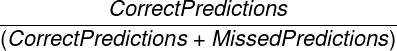
- F1-スコア: 精度とリコールの差

- 教育訓練ドキュメント: モデルの教育訓練に使用されるドキュメント数。合計ドキュメントの 80% が入力として使用されます。この 80% は各分類内でランダムに選択されます。
- テストドキュメント: モデルのテストに使用されるドキュメント数。これは、合計ドキュメントの残り 20% が入力として使用されます。
- 正しい予想: 予想確実性にかかわらず、モデルが正しく分類を予想した合計回数。
- 基準値を超える予想: この教育訓練モデルで選択された予想信頼性基準値を上回る予想の合計数。
- 基準値を超える正しい予想: この教育訓練モデルで選択された予想信頼性基準値を上回る正しい予想の合計数。
正しいとしてマークされるすべての予想は入力が正しく分類されたという前提に留意することが重要です。モデルの教育訓練に誤って分類されたドキュメントが使用されると、自動分類が不正確になる恐れがあります。以下にリストする教育訓練モデル階層は、潜在的な問題を明らかにする役に立つ可能性があります。
トレーニング済みモデル階層
教育訓練モデルには、教育訓練モデル階層が添付されており、それぞれに有益なデータが含まれています。これらは、教育訓練モデル階層セクションの教育訓練モデルオブジェクトレコードで確認できます。階層には、ドキュメント分類タイプを使用した教育訓練モデルの以下のファイルが含まれます:
- ドキュメントセット抽出結果 (documentset_extract_results.csv): このモデルの教育訓練のためにリクエストされた各ドキュメントの抽出結果。
- このファイルは、教育訓練プロセス中に一部のドキュメントが使用されなかった理由を確認するために最も役に立ちます。
- このファイル内のドキュメント ID およびメジャー / マイナーバージョンを使用して、Vault 内の適切なドキュメントを表示することができます。
- 失敗の理由として考えられる可能性のリストは、以下の抽出失敗の理由をご覧ください。
- モデル結果混同マトリックス (model_results_confusion_matrix.csv): ドキュメントの実際の分類 (X 軸) を TMF ボットの予想された分類 (Y 軸) と比較します
- 実際の分類と予想された分類が交わる対角線は、最も高い数字になります。
- 対角線の上下の数字は、混同を意味します。教育訓練モデルの混同の理由を理解するために、不正確な予測の数が多い分類を調査する必要があります。
- モデル結果ドキュメントタイプ頻度 (model_results_doctype_frequency.csv): 使用されたすべてのドキュメントタイプ、それぞれから使用された合計ドキュメント、および教育訓練 (80%) とテスト (20%) にそれぞれ使用された数をリストします。ドキュメントタイプごとの最小ドキュメント数の下の分類は、その他の不明にグループ化されます。
- モデル結果個別予想 (model_results_individual_predictions.csv): 実際のドキュメントタイプ、エンコード化されたドキュメントタイプ、各ドキュメントの上位 3 つの予想スコア、およびドキュメントが誤って分類されていたかどうかを示します。
- 実際のドキュメントタイプ列には、Vault の実際の分類がリストされます。エンコード化されたドキュメントタイプ列には、モデルに提供した実際の分類またはその他の不明 (教育訓練モデルのドキュメントタイプごとの最小ドキュメント数未満のドキュメントタイプ) の情報が提供されます。
- このファイルには、各ドキュメントタイプ予想に対して 1 つずつ、合計 3 つの予想スコアが表示されます。自動分類では最初の予想スコアのみが使用されます。このスコアが予想確実性基準値を上回る場合、そのドキュメントは自動分類されます。2 番目および 3 番目のスコアは、情報提供のみを目的としています。
- 最後に、誤った分類は、エンコード化されたドキュメントタイプおよび最初のドキュメントタイプ予想が一致するかどうかを示します。誤った分類の項目の表示をフィルタリングすると、既存のドキュメントの潜在的な問題をすぐに明らかにすることができます。例えば、教育訓練モデルの最初の予想スコアが 0.9999887 で、分類が誤っていた場合、ドキュメントタイプが Vault でも誤って分類される可能性があります。
- モデル結果パフォーマンス指標 (model_results_performance_metrics.csv): このレコードのモデルパフォーマンス指標データの CSV バージョン。
- モデル結果教育訓練セット (model_results_training_set.csv): 教育訓練 (全ドキュメントセットの 80%) および分類に使用された個別のドキュメントをリストします。このファイルは、特定の分類の教育訓練に使用されたドキュメントを確認したい場合、特に分類に頻繁に誤りが生じていることに気がついた場合に役に立ちます。
抽出失敗の理由
ドキュメントセット抽出結果 CSV ファイルは、抽出が失敗した以下のいずれかの理由を提供します:
- 言語が検出されませんでした: システムが言語を検出できませんでした
- 言語がサポートされていません: 検出された言語が英語ではありません
- 言語の検出が確実ではありません: システムの言語の検出が確実ではありません
- 有効なテキストがありません: ドキュメントに抽出可能なテキストがありません
- OCR 失敗 (PDF): PDF ファイルの光学式文字認識 (OCR) を完了できませんでした
- OCR 失敗 (複雑なイメージ): TIFF などの複雑な画像形式の OCR を完了できませんでした
- OCR 失敗 (シンプルイメージ): OCR は PNG や JPG などの単純なイメージ形式では完了できませんでした
- PDF レンダリング失敗: TMF Bot はドキュメントを PDF としてレンダリングできませんでした
- 現在のドキュメントタイプが無効です: このドキュメントのドキュメントタイプが現在有効ではありません
- 固定状態が見つかりません: ドキュメントに固定状態バージョンがありません
- このドキュメントタイプは故意に除外されています: ドキュメントがバインダーか、TMF ドキュメント内にあるか、最終 CRF ドキュメントタイプです
TMF ボットレポート
Vault には、展開されたモデルのパフォーマンスを評価するのに役立つ標準レポートとレポートタイプが含まれています。
予測レポートタイプ
予測レポートタイプを使用して、TMF ボットのパフォーマンスに関するカスタムレポートを作成することができます。
予想指標レポートタイプ
予想指標レポートタイプを使用して、訓練済モデルのパフォーマンスに関する詳細情報を表示できます。
TMF ボットの結果 - Excel レポートダッシュボード
この事前設定済みの予測レポートには、あなたの訓練済の抽出範囲、自動分類範囲、および自動分類成功率が含まれます。また、モデルのパフォーマンスを視覚化するダッシュボードを含む、このレポートの Excel テンプレートをエクスポートすることもできます。